NoSQL
Objetivo
O objetivo deste artigo é apresentar os conceitos sobre modelos de dados não relacionais, baseando em algumas IDEs do mercado, e quais as suas propostas para soluções de problemas e o que cada modelo representa.
Introdução
Asociedade está vivenciando um acúmulo de informações a cada instante, com uma quantidade de dados cada vez maior parece que não há mais espaço para guardar tantos dados e informação que só aumenta com o decorrer do tempo, e com isso acaba se tornando um grande desafio para os profissionais de TI saber lidar com esses dados.
Em seu artigo Wanzeller “Conforme Borkar et al.[17] descreve, as empresas passaram a monitorar compras de clientes, pesquisas de produtos, sites de relacionamento e diversas outras fontes para aumentar a eficácia do seu marketing e dos serviços ofertados aos clientes; governos e empresas estão rastreando conteúdos de blogs e tweets para realizar análise de sentimentos; e organizações públicas de saúde estão monitorando artigos de notícias, tweets e tendências de pesquisas na web para acompanhar o processo de epidemias. Esse grande volume de dados disponíveis e gerenciados leva a muitos desafios tanto para a academia quanto para a sociedade em geral”. (Diogo Wanzeler — 2013 p.1)
A tecnologia avança, ferramentas são criadas, novas versão de frameworks vem surgindo tudo para facilitar a vida de quem desenvolve softwares. Mas, um dos grandes desafios atualmente da área da Computação é, o processamento e a manipulação da quantidade excessiva de dados, no termo Big Data. Esse crescimento começou já no período do surgimento da Web 2.0, que se baseia em uma rede onde o usuário não apenas usufrui dela e sim contribui com seu conteúdo na rede.
Big Data
Big Data (Data Analytics) ou Ciência dos Dados descreve o imenso volume de dados armazenados, onde uma enorme quantidade de registro é criada simultaneamente. Exemplo: dados em redes sociais, economia, IOT, bancos, blogs, notícias, dados de transações, dados privados, dados públicos e por aí vai uma infinidade de dados.
De acordo com Hekina que descreve o big data como: “O termo Big Data é tão amplo quanto seu nome sugere”. Para contextualizá-lo e dar sentido a ele, caro leitor, segue uma breve explicação: nós vivemos em uma Era em que, a (apenas) cada um ano e meio, se gera a mesma quantidade de dados já criados pela humanidade em todos os tempos.
O Vs presente no big data são:
-
Volume: quantidade de dados acomulados;
-
Variedade: meios de propagação do tipo destes dados;
-
Veracidade: verificar se estes dados são confiáveis;
-
Valor: resultado obtido com o uso das ferramentas do big data
O objetivo das ferramentas do big data é a manipulação de dados estruturados e não estruturados, com o intuito de extrair valor destas correlações, tentando fazer uma análise destes dados e compreendê-los para assim poder chegar a uma conclusão ou resultado esperado. O tratamento desses dados é feito com algoritmos inteligentes, que nada mais são sequência de instruções que tem como objetivo chegar a um resultado esperado, uma solução para um problema.
O tratamento dos dados no Big Data é feito com a utilização de algoritmos inteligente, utilizando o aprendizado de máquina (Machine Learning), para a coleta, processamento, separação destes dados. Alguns destes algoritmos para o aprendizado de máquina são: rede neural, árvore de decisão e classificação linear.
O que é NoSQL ?
NoSQL (Not Only SQL — Não Somente SQL) é um termo genérico utilizado para chamar uma classe definida de coleção de dados. O termo NoSQL foi reintroduzido no início de 2009 por um funcionário do Rackspace, Eric Evans, quando Johan Oskarsson da Last.fm queria organizar um evento para discutir bancos de dados open source distribuídos. O nome — uma tentativa de descrever o surgimento de um número crescente de banco de dados não relacionais, que não tinham a preocupação de fornecer garantias ACID — faz referência ao esquema de atribuição de nomes dos bancos de dados relacionais mais populares do mercado: MySQL, MS SQL, PostgreSQL etc (Wikipédia).
Essa coleção de dados vem tendo um crescimento bem favorável nos últimos anos, devido a algumas limitações existentes que os bancos de dados convencionais (SQL) têm. O NoSQL foi projetado para ser ter alta escalabilidade, alta disponibilidade para armazenar dados semi estruturados com alto desempenho. Vejamos algumas das características que diferencia o NoSQL do SQL são:
-
Não há relacionamento entre as tabelas;
-
Schema Less;
-
Linguagens independentes;
-
Versionamento e gerenciamento de transações;
-
Model less rodam em ambientes paralelos e distribuídos com alta disponibilidade e intolerância a falhas;
-
Soluções Poliglotas onde uma mesma aplicação pode ter várias soluções coleções de dados associadas conforme a funcionalidade da aplicação.
-
Alta performance;
-
Alta escalabilidade;
-
Distribuído
Teorema de CAP
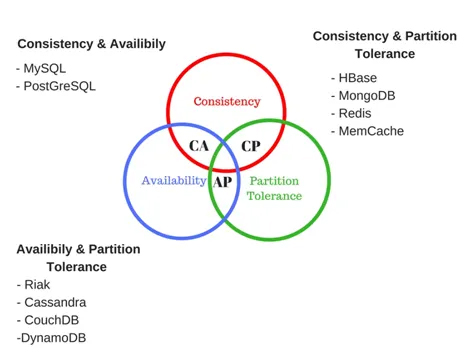
“O teorema de CAP (também chamado de Teorema de Brewer’s[12]) propõe um modelo mais realístico do que acontece na prática, para entendê-lo teremos que entender a fundo o que as propriedades ACID propõem.” (Renato Molina).
Conforme mostrado acima, a imagem do teorema representa três requisitos que influenciam o sistema de dados distribuídos, sendo eles: consistência, disponibilidade e tolerância a falhas (consistency, availability and partition tolerance).
Consistência — Todos os clientes enxergam os mesmos dados, ou seja, é um comportamento onde o sistema garante a leitura dos dados e mesmo estes dados terem sido atualizados. Mesmo que alguém tenha feito uma mudança no dado ou se esse dado tenha sido criado em algum outro nó, o cliente sempre verá estes dados atualizados.
Disponibilidade — Refere-se o sistema estar disponível ao cliente e estar operando mesmo falhas, ou seja, quando o cliente lê um registro ou escrever algum dado, em nenhum momento ele poderá receber uma mensagem “O sistema encontra-se indisponível!”, imagina essa mesma situação em um usuário do Twitter, ao enviar uma mensagem receber em sua tela uma informação dessas. Isso não quer dizer que o sistema não pode conter erros ou falhas em um nó, isso quer dizer que, mesmo ocorrendo uma falha em um nó ou um nó ficar offline, o sistema deverá continuar disponível ao cliente, porque ele precisa manter essa disponibilidade.
Tolerância a Partição — Tolerância à falha significa que, mesmo que o sistema tenha uma falha de rede ou conectividade que seja, o mesmo deve continuar funcionando. Pode se dizer que um sistema que tenha alguma falha de hardware/software a aplicação deverá estar disponível para o cliente, sendo assim, é um sistema tolerante a falhas.
O banco de dados NoSQL possui quatro modelos de dados principais que são:
-
Modelos Orientado a Documento (MongoDB, CouchDB)
-
Modelos Orientado a Chave — valor (Memcached, Riak e Redis)
-
Modelos Orientado a Colunas (Cassandra, HBase e Hypertable)
-
Modelos Orientado a Grafo (Neo4J, InfoGrid, AllegroGraph e Virtuoso).
Modelos Orientado a Documento
Este modelo de dados tem como objetivo armazenar coleções de documentos encapsulados semi estruturados em formato JSON ou XML. Um documento, nada mais é do que um objeto contendo um identificador único com um ou mais pares de campo/valor, que podem ser strings, listas ou documentos aninhados. As principais soluções que adotam esse modelo são: CouchDB e MongoDB, ambos utilizam JSON para armazenar os dados.
Modelos Orientado a Chave-valor
Esse modelo armazena dados indexados por um valor chave, esse tipo de banco de dados é otimizado para cargas de trabalho com um consumo muito alto de leitura, pois sendo, redes sociais, jogos e etc. “O armazenando deste tipo é semelhante ao uso de mapas, ou dicionários, onde os dados são endereçados por uma única chave, permitindo aos clientes colocar e solicitar valores por chaves.” (Ivan Friess — 2013). Alguns exemplos são:
Modelos Orientado a Colunas
Os modelos Orientado a Colunas oferecem forte consistência, mas,não garante alta disponibilidade. Os dados são armazenados em colunas e cada coluna de dado é um índice no banco. Alguns exemplos são:
Modelos Orientado a Grafos
Neste modelo os dados são armazenados em nós de um grafo, de acordo com Wanzeller “Esse tipo de banco é especializado em manter dados fortemente ligados. O Twitter armazena as relações entre os seus usuários no seu próprio banco de dados baseados em grafos, o FlockDB, que é otimizado para listas de relações muito grandes, leituras e escritas [27]. Alguns exemplos são: Neo4J, infoGrid e FlockDB [9].” (Diogo Wanzeller 2013).
Empresas que utilizam modelos de dados NoSQL
Escolher o modelo a ser utilizado em uma aplicação vai depender muito da sua aplicação. NoSQL não veio para substituir o SQL, muito pelo contrário SQL ainda continua “vivo” e muito bem utilizado em grandes aplicações, ainda há uma necessidade muito grande na utilização de bancos como SQL.
Por isso, que vai depender muito da aplicação, aplicações que utilizam NoSQL são aquelas aplicações que precisam ter um desempenho e armazenamento maior quando há um volume de dados muito grande, precisa ter escalabilidade, flexibilidade, disponibilidade e baixo custo, essas aplicações de fato se torna recomendado o uso do modelo de dados como NoSQL.
Netflix
A Netlix é uma empresa provedora e produtora global de filmes e séries de televisão, via streaming, seus usuários chegam a mais de 100 milhões. A empresa utiliza os serviços de nuvem da AWS e o banco de dados Amazon Simple DB.O Amazon Simple DB é um armazenamento de dados NoSQL altamente disponível. Para sistemas baseados em Hadoop, o Apache HBase é uma solução de banco de dados distribuída orientada por colunas conveniente e de alto desempenho. Sai mais no artigo escrito no blog Netflix Tech Blog publicado no Medium sobre as tecnologias cloud e bancos NoSQL, que utilizam em sua plataforma. (https://bit.ly/2LhM5kR).
X - antigo Twitter
De acordo com uma publicação do Kevin Weil SVP Product do Twitter referente a bancos de dados NoSQL e como a empresa usa em suas aplicações. Segundo Weil, os usuários do Twitter geram 12 terabytes de dados por dia — cerca de quatro petabytes por ano e essa quantidade está se multiplicando a cada ano. Algumas das tecnologias utilizadas para soluções NoSQL são, Hadoop, Cassandra e FlockDB.
Meta antigo Facebook
A rede social Facebook não só utiliza modelos NoSQL como também desenvolveu sua própria solução de dados o Cassandra. O Cassandra foi criado com o intuito de resolver um problema inicialmente, de otimização de buscas pelo Facebook. De acordo com Avinash Lakshman um antigo engenheiro de software do Facebook informa em uma publicação técnica “Este desafio é sobre o armazenamento de índices reversos de mensagens do Facebook que os usuários do Facebook enviam e recebem enquanto se comunicam com seus amigos na rede do Facebook.
A quantidade de dados a serem armazenados, a taxa de crescimento dos dados e a exigência de atendê-los dentro de SLAs estritos tornaram muito aparente que uma nova solução de armazenamento era absolutamente essencial. A solução necessária para escalar de forma incremental e de maneira econômica.” (Avinash Lakshman — Cassandra — A structured storage system on a P2P Network).
Conclusão
Eu citei três exemplos de empresas que utilizam o modelo de dados NoSQL em suas aplicações, mas existem várias empresas que também utilizam, por exemplo, Globo.com, Linkedin, Totvs entre outras. O que essas empresas têm em comum? Além da grande quantidade de dados gerados, precisam ter uma escalabilidade, desempenho e dentre outras soluções nas quais descrevo no inicio do artigo. Por isso, entre escolher SQL ou NoSQL isso vai depender muito da sua aplicação e da arquitetura que está sendo construída.
Cada caso é um caso, mas eu não descartaria a ideia de utilizar modelos como NoSQL caso isso seja levado em conta os cenários acima na qual descrevi. Vale lembrar também que, não é só porque muitas empresas grandes que estão utilizando esse modelo de dados que sua empresa deve utilizar também. Por mais barato que seja utilizar NoSQL ao invés do SQL, temos que pensar em recursos, pessoas que estão aptas a trabalharem com esse tipo de tecnologia e claro investirem em treinamentos e conhecer um pouco mais sobre essas tecnologias novas e o que se pode utilizar. É sempre bom estarmos antenados com as mudanças no mercado e, sempre pensar em como se beneficiar disso.
Referência
-
[slideshare.trabalho-no-sql-aricelio-de-souza]https://pt.slideshare.net/Celio12/trabalho-no-sql-aricelio-de-souza